Contest Flow 성능 개선
개요
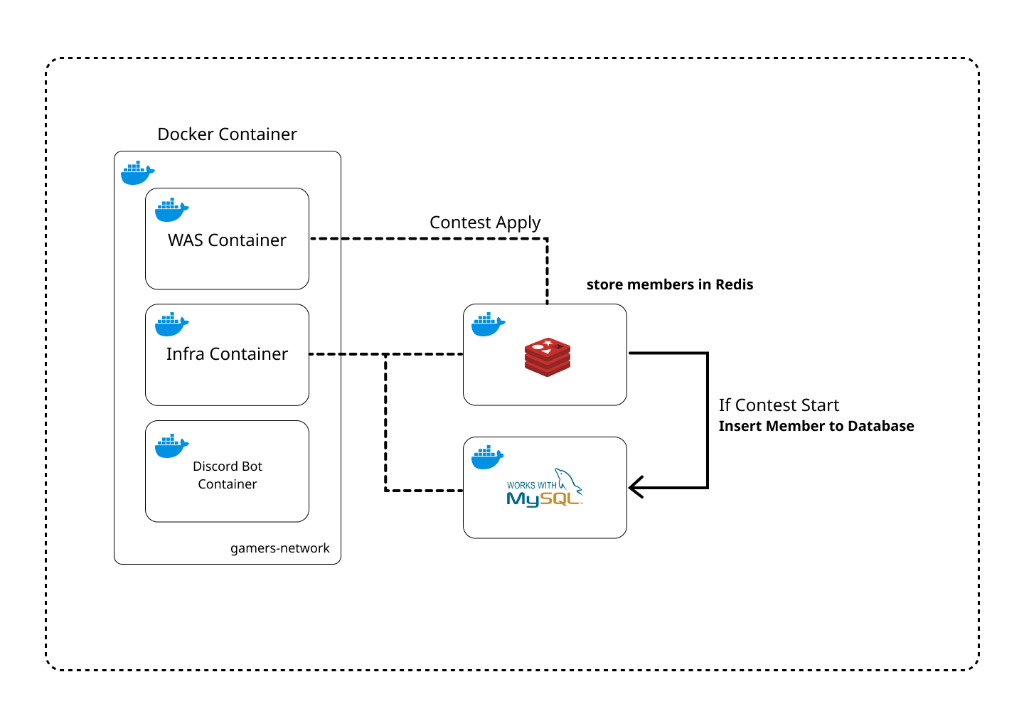
GAMERS 서비스에서 Custom Match 를 시작시킬 때, 아래와 같은 Flow 를 가지고 있다.
- Contest 를 시작시킬만한 권한이 있는지 확인
- 해당 Contest 를 시작할 수 있는 상태에 있는지를 확인
- Redis 에 승인되어있는 신청서들을 가져와 DB 로 개별 Insert
- Insert Query 에 대해서 Transaction 을 개별로 걸어놓음
- Contest Domain 에 설정되어있는 State Machine 을 통해서 Contest 에 대한 Status Update
- Redis 에 Contest 와 관련되어있는 Application 에 대해서 삭제를 한다.
- SCAN 방식을 사용
Start Contest 에 대해 Test 를 진행했을 때, Test 에 대한 속도가 많이 늦고 Memory 에 대한 갑작스레 점유율이 높아져, 주요 로직에 대해서 테스트를 해보았다.
- 개별 Insert
- Redis 에 저장되어있는 Contest 관련 Application 삭제
개별 Insert Logic ( Go Benchmark 사용 )
| Member Count | Method | Time( s/op ) | Memory ( B/op ) | Allocation Count ( alloc / op ) |
|---|---|---|---|---|
| 10 | LoopSave | 0.00423 | 51,779 | 544 |
| 50 | LoopSave | 0.01381 | 250,350 | 2,624 |
| 100 | LoopSave | 0.02334 | 498,588 | 5,225 |
| 200 | LoopSave | 0.04244 | 994,826 | 10,425 |
// * contest_member_database_adapter.go
err := c.db.Transaction(func(tx *gorm.DB) error {
for _, member := range members {
if err := member.Validate(); err != nil {
return err
}
if err := tx.Save(member).Error; err != nil {
return err
}
}
return nil
})Clear Applications
| Noise Key | Member Count | Method | Time ( s/op ) | Memory ( B/op ) | Allocation Count ( alloc / op ) |
|---|---|---|---|---|---|
| 0 | 50 | SCAN | 0.000295 | 14,695 | 282 |
| 0 | 100 | SCAN | 0.000600 | 29,331 | 553 |
| 10,000 | 50 | SCAN | 0.020009 | 63,195 | 1,758 |
| 10,000 | 100 | SCAN | 0.021694 | 79,632 | 2,242 |
| 100,000 | 50 | SCAN | 0.142613 | 445,458 | 10,803 |
| 100,000 | 100 | SCAN | 0.146344 | 467,877 | 11,629 |
Contest 를 시작하는 권한은 Contest Staff 들밖에 없으므로, 속도적인 측면은 개선을 해야할 우선순위에 있어서 높은 부분은 아니었다.
하지만 Memory 점유율에 있어서 운영 VM 의 Spec 을 확인하였을 때, 1코어 4GB 로 부하가 걸릴 시, 4GB 를 초과할 수 있다고 생각하였다.
따라서 Batch Insert 와 Redis 내에서 Application 을 가져오는 Logic 을 개선해야겠다고 생각하였다.
Redis SCAN 방식에 대한 고찰과 개선
간단하게 생각하면 Cursor 를 사용한 Pagination 이라고 생각하면 좋다.
Keys * 명령어를 사용하게 되면, Data 가 1만건이라고 가정하였을 때, 1만건 중 원하는 Data 를 전부 가져오는 Logic 이다.
하지만 이때 1만건에 대해서 전부 가져오기 위해서는 Network 대역폭도 사용하며, 해당 1만개를 다 찾기 위해서 Redis 의 Thread 를 점유하고 있게 된다.
알다싶이 Redis 는 단일 Thread 로 동작하기 때문에, 많은 시간 Thread 점유를 하고 있는 것은 다른 작업에 대해서 수행하기까지 시간이 걸린다.
따라서 Pagination 방식인 SCAN 방식이 나오게 되었습니다.
Cursor 를 사용하여, Redis 가 데이터의 일부만 가져오고, 추후 Cursor 를 업데이트하며 데이터를 가져오는 방식을 사용할 수 있다.
하지만 우리 Service 에서 해당 방식이 원하는 Data 를 가져올 때까지 Cursor 를 계속해서 업데이트하여 가져오는 방식이 된다.
아래의 플로우를 참고해주면 이해하기 좋을 것이다.
- Memory 에서 Any Key 에 대해서 지정된 개수 ( Count 개수 ) 만큼 Cursor 에 해당하는 Page 의 데이터를 Load 해온다.
- 해당 Count 개수 중,
contest:*패턴에 맞는 Key 에 대해서 검사를 한다. - 맞는 것만 Client 에게 전달한다.
여기에서 우리가 찾는 Key가 5개지만 Noise Key 가 10만개가 있다고 가정할 시, 10만개의 Noise Key 를 Load 해와서 검사한 뒤, Client 에게 전달하는 작업을 반복해야한다.
따라서 이 방식을 개선할 방안으로 Indexing 을 적용하는건 어떨까? 라는 생각을 하게 되었습니다.
이를 위해서는 SET 자료구조를 사용하는 것이 옳았고, Contest 에 대해서 중복되는 사용자가 참가할 수 없기에 SET 자료구조가 더 적합하다고 생각했습니다.
아래의 코드를 보면서 설명을 계속하면, 특정 Contest 에 대한 Key 값을 받아온다.
그리고 해당 Key 에 대해서 SET 명단을 조회해서 ID 를 가져올 수 있도록 SMembers 명령어를 사용하여 가져온다.
pendingKey := utils.GetPendingKey(contestId)
acceptedKey := utils.GetAcceptedKey(contestId)
rejectedKey := utils.GetRejectedKey(contestId)
pendingCmd := pipe.ZRange(ctx, pendingKey, 0, -1)
acceptedCmd := pipe.SMembers(ctx, acceptedKey)
rejectedCmd := pipe.SMembers(ctx, rejectedKey)
_, err := pipe.Exec(ctx)
if err != nil {
return nil, err
}이렇게 가져온 Key들에 대해서 Pipe 를 이용해 1번의 Rounded-Trip 으로 Data 를 받아온다.
받아온 Data 를 통해서 Key 를 조합한 후, 직접적으로 Data 에 대해서 접근하는 방식을 사용했다.
실제로 이 방식을 사용했을 때, 아래처럼 Test 결과가 나오는 것을 확인했다.
Direct 접근 방식
| Noise Key | Member Count | Method | Time ( s/op ) | Memory ( B/op ) | Allocation Count ( alloc / op ) |
|---|---|---|---|---|---|
| 0 | 50 | Direct | 0.000298 | 19,467 | 361 |
| 0 | 100 | Direct | 0.000364 | 37,688 | 664 |
| 10,000 | 50 | Direct | 0.000314 | 19,467 | 361 |
| 10,000 | 100 | Direct | 0.000353 | 37,689 | 664 |
| 100,000 | 50 | Direct | 0.000306 | 19,468 | 361 |
| 100,000 | 100 | Direct | 0.000342 | 37,688 | 664 |
SCAN 접근 방식
| Noise Key | Member Count | Method | Time ( s/op ) | Memory ( B/op ) | Allocation Count ( alloc / op ) |
|---|---|---|---|---|---|
| 0 | 50 | SCAN | 0.000295 | 14,695 | 282 |
| 0 | 100 | SCAN | 0.000600 | 29,331 | 553 |
| 10,000 | 50 | SCAN | 0.020009 | 63,195 | 1,758 |
| 10,000 | 100 | SCAN | 0.021694 | 79,632 | 2,242 |
| 100,000 | 50 | SCAN | 0.142613 | 445,458 | 10,803 |
| 100,000 | 100 | SCAN | 0.146344 | 467,877 | 11,629 |
위의 Table 을 분석했을 때, 아래와 같은 결과를 볼 수 있었다.
Direct 방식은 Noise Data 가 10만개가 있어도, 응답속도가 0.3ms 로 일정하게 유지되는 것을 확인할 수 있었다.
하지만 Scan 방식은 Noise Data 에 비례해서 응답 속도가 140ms 까지 느려지는 것을 확인할 수 있었다.
따라서 10만개의 Noise Data 환경에서 Direct 방식이 약 460배 빠른 것을 확인할 수 있다.
또한 SCAN 방식은 Noise Key 에 따라서 Memory 를 사용하는 것을 볼 수 있고, Direct 방식은 필요한 Key 에 대해서만 Memory Load 를 하는 모습을 볼 수 있다.
개별 Insert 의 문제 파악과 Batch Insert 방식으로의 개선
GAMERS 로직 중, 개별 Insert 를 하는 부분이 있다.
현재 나의 운영 서버는 1코어, 4GB 의 Memory 를 가진 VM 이고, 유휴 Connection 최대 수가 10개, 동시 열 수 있는 최대 Connection 은 100개로 설정되어 있다고 가정을 했을 때, 문제점이 생긴다.
// * GAMERS-BE/global/config/config.go
sqlDB.SetMaxIdleConns(10)
sqlDB.SetMaxOpenConns(100)
sqlDB.SetConnMaxLifetime(time.Hour)- Network Round-Trip 이 다수 발생한다.
- Application 과 MySQL 간의 Network 가 ( Member Count * 2 ) 만큼 발생한다.
- 1코어 VM 을 생각했을 때, Context Switching 비용이 발생한다.
- Application → MySQL → Application …
- InnoDB 의 Buffer Pool 에 압력이 가해진다.
- 개별 Insert 마다 Page 의 수정이 가해지는데, 이럴 때마다 dirty page flush 가 빈번해지고, 추가 I/O 를 유발할 수 있다..
따라서 Contest 에 참여할 수 있는 Member 들에 대해서 Batch Insert 를 시행하여 Test를 진행해보았다.
| Member Count | Method | Time( s/op ) | Memory ( B/op ) | Allocation Count ( alloc / op ) |
|---|---|---|---|---|
| 10 | CreateInBatches | 0.00163 | 15,239 | 171 |
| 50 | CreateInBatches | 0.00216 | 51,351 | 571 |
| 100 | CreateInBatches | 0.00272 | 96,402 | 1,071 |
| 200 | CreateInBatches | 0.00344 | 191,775 | 2,116 |
위는 Batch Insert 를 설정해서 속도와 Memory 사용량을 측정한 표와 아래는 개별 Insert 를 설정해서 속도와 Memory 를 비교하였다.
| Member Count | Method | Time( s/op ) | Memory ( B/op ) | Allocation Count ( alloc / op ) |
|---|---|---|---|---|
| 10 | LoopSave | 0.00423 | 51,779 | 544 |
| 50 | LoopSave | 0.01381 | 250,350 | 2,624 |
| 100 | LoopSave | 0.02334 | 498,588 | 5,225 |
| 200 | LoopSave | 0.04244 | 994,826 | 10,425 |
200명을 기준으로 속도는 약 12배정도 향상되었으며, 메모리 사용량을 5배 이상 절감하는 결과를 가져올 수 있었다.
결론
본론에서는 Batch Insert 와 Direct 접근 방식이 개선은 하였다고 볼 수 있지만, 여전히 문제는 있었다.
Batch Insert 를 진행할 때, Batch 단위밖에 Error 를 확인할 수 있고, 내부적으로 어디에서 Error 가 발생하는지에 대해서는 확인이 어려웠다.
이를 처리하기 위해서는 추후 포스팅에서 다뤄보고자 한다.
그리고 Batch Insert 를 사용하면, Memory 에 모아서 단번에 DB 로 전송하기 때문에, Memory 에 부하가 걸릴 수 있지만, GAMERS 에서는 그정도로 많은 참여자를 DB 로 전송할 일이 없어서, Batch Insert 를 선택하는 근거가 되었다.
하지만 여러 Transaction 이 Batch Insert 를 하면 Index Lock 범위가 넓어져서, Deadlock 이 걸릴 가능성이 있다.
여기에서 GAMERS 서비스의 PK 가 순차적으로 설정이 되어있어, Deadlock 이 걸릴 가능성을 조금이라도 낮출 수 있었다.
Reference
- https://dev.mysql.com/doc/refman/8.4/en/insert-optimization.html
- https://dev.mysql.com/doc/refman/8.4/en/optimizing-innodb-bulk-data-loading.html
- https://medium.com/@benmorel/high-speed-inserts-with-mysql-9d3dcd76f723
- https://nickb.dev/blog/opitimizing-innodb-bulk-insert/
- https://redis.io/docs/latest/commands/scan/