[Java] Synchronized, Volatile, Atomic
개요
카카오 테크 캠퍼스에서 과제로 부여받은 SpringBoot Memory ( HashMap ) 을 이용해서 데이터 저장소를 대체하는 과제에서 문제가 생겼다.
필자는 데이터 저장소를 대체하기 위해서 Collection 중 HashMap 을 선택하였고, 해당 HashMap 에 대해서 접근할 때, Record 별로 고유한 ID 를 부여하기 위해서
private AtomicLong id;를 선언했다.
그렇게 과제제출을 하고 멘토님께 피드백을 받을 때, 왜 이걸 사용하셨나요? 라고 물음이 왔을 때 그에 대한 대답을 하지 못했기 때문에 이 글을 작성하면서 해당 물음에 대해 대답을 해보려고 한다.
내용
우선 내가 지금 왜 AtomicLong 을 사용하였는가에 대해서 설명하고자 한다.
DB 를 대체하기 위해서 HashMap 을 사용했다고 했는데, 이때 SpringBoot 는 각 API 요청에 따라서 개발자가 지정한 Thread 의 개수에 따라, 요청 Thread 가 만들어진다.
요청 Thread 들은 자신들의 요청을 수행하기 위해서 필자가 만든 DB 에 접근을 할텐데, 이 경우에 동시성 문제가 발생할 수 있다.
따라서 HashMap 같은 경우, Thread 들의 요청에 의해서 동시성 문제가 일어나지 않도록, Thread-safe 한 ConcurrentHashMap 을 사용하였다.
여기까지는 괜찮았지만, 이제 HashMap 에 들어갈 Record들에 대해서 고유한 ID 를 부여해주고자 하였다.
물론 DB 를 연결해서 DB 에서 정해주는 값을 사용해도 되지만, 지금은 HashMap 으로 대체하고 있기 때문에 필자가 설정한 ID 를 사용하고자 한다.
그렇다면 해당 ID 조차도 경합 문제 즉, 동시성 문제가 발생할 수 있다는 얘기인데, 왜냐하면 Thread 들이 전부 값을 저장하는 작업을 수행한다고 하면, 작업을 수행할 때, 필자가 설정한 ID 값에 대해서 접근을 할 것이고, 그 과정에서 중복된 값이 들어갈 확률이 있다는 것이다.
Java 에서 필드 변수를 설정하고 값을 넣을 경우, Heap Memory 에 값을 저장하게 되는데, 이런 Heap Memory 는 공유 Memory 이다.
이때 Thread 가 접근하면 Race Condition 이 발생할 수 있으며, 해당 값에 대해서 확신을 갖지 못하게 되는 것이다..

Thread 의 공유 자원 처리 방식에 대해서 알아보고 동기화 문제 해결책에 대해서 설명하고자 한다.
Thread 는 Memory 의 Data 를 가져다가 Cache 에 올려놓고 연산을 한다.
연산이 끝난 뒤, 해당 연산 결과를 다시 Memory 에 반환을 하는데, 이때 각 Thread들끼리 연산을 하면서 처음 가져왔던 값이 아닐 수 있는 것이다.
이때문에 Race Condition 이 발생하게 되고, 다른 값이 Memory 에 존재하게 되어, 값이 뒤덮이는 것이다.
따라서 Java 에서는 이러한 동기화 문제를 3개의 해결책을 제안하여 해결하고자 하였다.
- Synchronized
- Volatile
- Atomic.class
하나하나 알아보고자 한다.
Synchronized
이는 선언된 Method 의 Code Section 에 Lock 을 건다. 접근하는 Thread들에 대해서 Block / Suspended 상태로 변경하게 되는데, 이 과정에서 전부 자원이 소모된다. Thread 들이 Blocking 되는 과정, Resuming 되는 과정 전부 자원이 소모되기 때문이다.
그렇다면 100개의 Thread 가 해당 Synchronized 코드 영역에 접근을 하게되면, 99개의 Thread 는 자원소모가 있다는 것이며, 이는 성능 저하로 이어진다.
synchronized void increase() {
count++;
System.out.println(count);
}예시로 적어놓은 위의 코드를 실행하기 위해 Lock 을 걸어놓고, 해당 코드를 실행하기 위해서 99개의 Thread 가 기다리고 있는 것은 굉장히 자원소모라고 생각이 들지 않는가?!
물론, 필요 시에 해당 방식은 좋은 접근이 될 수 있겠지만, Thread 들을 관리하는 과정에서 자원소모가 드는 것은 굉장히 아쉬운 부분이다.
Volatile
해당 개념은 굉장히 인상 깊었었던 기억이 난다.
이유는 Java 에서 어떤 변수에 volatile 키워드를 붙이면, 해당 변수는 모든 읽기와 쓰기 작업이 CPU Cache 가 아닌 Main Memory 에서 일어나게 되기 때문이다!
이로 인해 변수에 가시성을 보장할 수 있게 된다. 따라서 공유 변수 불일치 문제가 발생하지 않게 되는 것이다!
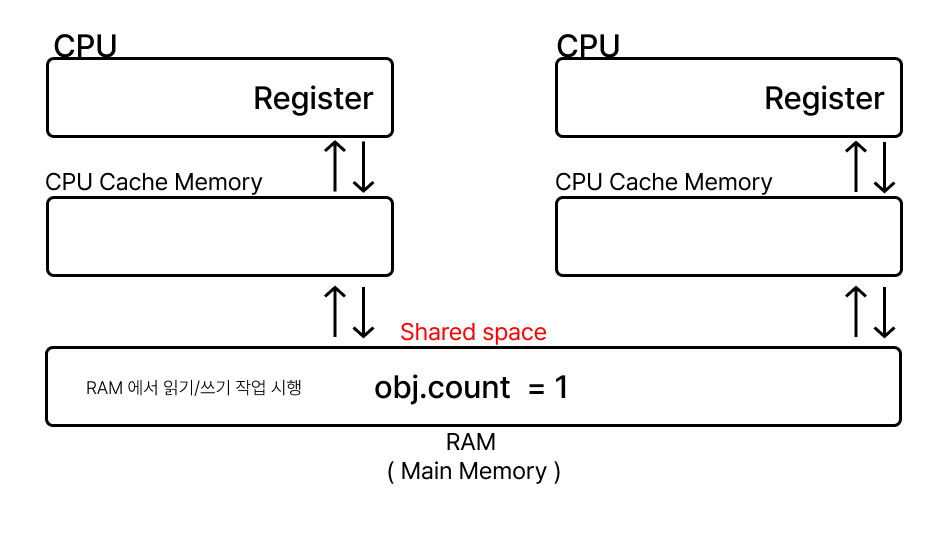
개요에서 걱정했던 공유 변수 불일치 문제가 해당 volatile 로 해결이 되는데, 여기서 주의해야 할 점이 있다.
volatile 만 설정하는 것이 아니라, 이와 함께 synchronized 를 사용하면 synchronized 만 썼을 때, 발생했던 자원소모 문제가 해당 volatile 로 어느정도 개선해나갈 수 있는 면모를 보여준다.
Atomic
마지막으로 Atomic 이다.
Atomic 클래스는 자원 소모 비용이 상대적으로 적은 편이다.
어떤 Thread 도 suspended 되지 않으며, Context Switch 를 피할 수 있다.
이러한 방식이 가능한 이유는 non-blocking 방식 덕분이다!
그리고 Atomic 은 CAS ( Compare And Swap ) 알고리즘을 사용할 수 있는데, 원자적 함수를 실행할 수 있다는 부분이 가장 큰 장점이다.
CAS 알고리즘은 들으면 굉장히 어려워 보이지만, 단순히 기존 값과 변경 값을 바꾸는 것이다.
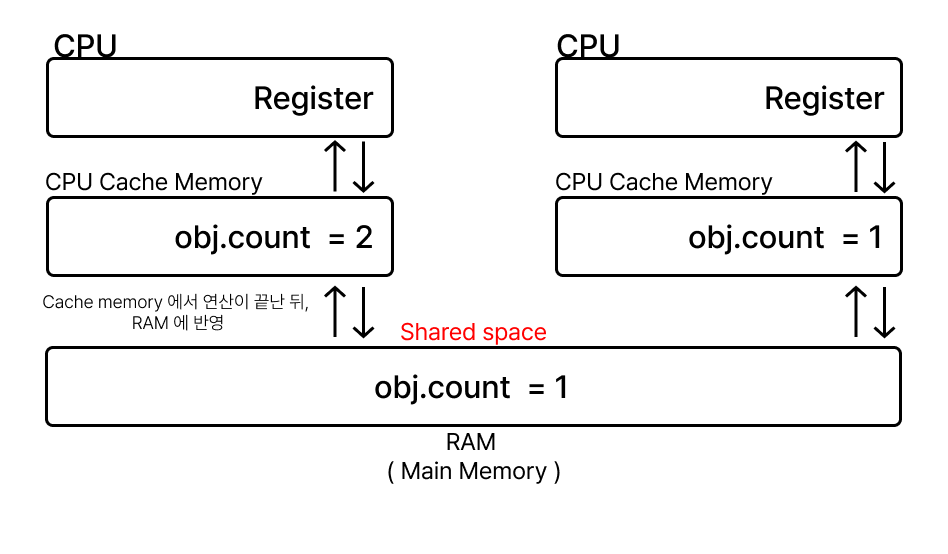
개요에서 말했듯이, 현재 Memory 가 가지고 있는 값과 CPU Cache Memory 에서 처음에 가져온 값 (a=1) 과 같다면, 변경할 값 (b=2) 을 반영해서 True 를 반환한다.
이렇게 True 가 반환되면, RAM 에 있는 값이 변경할 값(b=2)으로 바뀌어 지는 것이다.
만약에 연산을 수행하는 Thread 가 여러 개 일 경우에 Memory 의 Data 와 Thread Data 가 불일치하는 경우가 생길 수 있는데, 이럴 때에는 False 를 반환하게 된다.
public class AtomicLong extends Number implements java.io.Serializable {
private static final long serialVersionUID = ...;
private static final Unsafe U = Unsafe.getUnsafe();
private static final long VALUE = U.objectFieldOffset(AtomicLong.class, "value");
private volatile long value;
public final long incrementAndGet() {
return U.getAndAddLong(this, VALUE, 1L) + 1L;
}
}
public final class Unsafe{
@IntrinsicCandidate
public final long getAndAddLong(Object o, long offset, long delta) {
long v;
do {
v = getLongVolatile(o, offset);
} while (!weakCompareAndSetLong(o, offset, v, v + delta));
return v;
}
}위의 코드는 실제로 Atomic class 의 객체 중 하나인 AtomicInteger 를 들여다 본 코드 내용이다.
단순히 이 부분만 본다면, CompareAndSetLong 이 부분으로 방금 전 CAS 알고리즘이 시행되구나 라는 생각만 했을 것이다.
하지만 https://velog.io/@chullll/JAVA-Atomic-%EA%B3%BC-%EB%8F%99%EC%8B%9C%EC%84%B1
해당 포스트를 보고나서, 무한 루프 부분에 조금 더 집중해서 보게 되었고, 위의 포스트에서 말씀하신 것처럼 synchronized 와의 성능 비교문에 대해서 의문을 갖게 되었다.
필자 또한 synchronized 는 코드 섹션에 Lock 을 걸어, Thread 가 Blocking / Resuming 되는 자원 소모를 하고 있지만, Atomic 은 Non-Blocking 방식을 구현하고 있으며, 비록 무한 Loop 를 걸고 있어도, True 만 반환되면 다음 작업을 수행할 수 있다는 부분에서 synchronized 보다 성능 상 이점을 가지고 있다고 생각하였다. ( 위의 포스트에서 말씀하셨던 내용과 동일한 내용이다. )
class AtomicInteger {
private volatile int value;
public AtomicInteger(int initialValue) {
value = initialValue;
}
public AtomicInteger() { }
public final int get() {
return value;
}
public final void set(int newValue) {
value = newValue;
}
...
}이때, AtomicInteger 의 내부를 확인해보면, volatile 이라는 변수를 볼 수 있을 것이다.
해당 변수를 통해서 get 과 set 을 Atomic 연산으로 만들어주었으며, 이 코드 덕분에 Race Condition 이 일어나지 않을 수 있었다.
이 모든 것을 종합하였을 때, 필자가 Atomic Class 를 쓴 이유는 원자적 연산을 수행해줌으로써, Race Condition 이 일어나지 않도록 도와주기 때문에 Atomic Class 를 사용하였다고 피드백 주신 분께 답변을 드릴 수 있을 것 같다.
느낀 점
단순히 짠 코드여도, 카테캠에서 멘토멘티를 통해 내가 이 코드를 왜 짰는지에 대해서 물어봐주시는게 정말 크다고 생각했다.
또한 Atomic 이라는 개념을 배우기 위해서 다른 개념들을 이해하고, 그 과정에서 왜 Atomic 이 선택되었는가를 공부하면서 느끼게 되었다.
필자가 혼자 공부할 때에도 이렇게 왜 썼는가에 대해서 의문을 가지고, 그에 대해 설명할 수 있는 개발자가 되기를 바라며 포스팅을 마친다.